Pairwise Meta-Analysisアプリの取扱説明書
RevManが有料化し、メタアナリシス初心者が、統計処理をするハードルが上がっています。メタアナリシスの実施にあたっては、リサーチクエスチョンを決め、プロトコルを作り、きちんと系統的レビューを行うということが不可欠ですが、統計処理もまた不可欠です。
このウェブアプリを作成するにあたり、メタアナリシスの初心者が直感的に簡潔にペアワイズ・メタアナリシスを行うことができるようになることを目指しました。それでいて、論文化するのに必要十分な機能を設けることに注力しました。
このウェブアプリでは、ロング形式のデータをエクセルからコピー&ペーストで入力することで自分のデータをすぐに解析を行えます。プリセットのデータで解析をしてみることもできます。デフォルトの設定のまま統計解析してもよいですし、パラメーターを変更することもできます。Forest plotのタイトルなども編集できます。サブグループ解析もできます。Contour-enhanced funnel plotも出力可能です。
インストールや登録は不要です。気軽にペアワイズ・メタアナリシスを実施できます。統計ソフトに不慣れな初学者が系統的レビューとメタアナリシスを始める手助けとなりますように。
目次
DO NOT START HERE: ここから始めてはいけない
Cochrane Handbookのメタアナリシスの統計処理の章を見ると、1番最初にDO NOT START HERTE(ここから始めてはいけない)と書いてあります。メタアナリシスは、forest plotのイメージが強く、その大前提となる、よいリサーチクエスチョンを作り、プロトコルを策定し、系統的レビューを行うということが軽視されがちだからです。
ここでも、しっかりとした系統的レビューとメタアナリシスを実施するためには意義のあるリサーチクエスチョンを作り、きちんとプロトコルを策定して、事前登録し、系統的レビューを網羅的に徹底的に行うことが重要であることを強調しておきます。
一方で、メタアナリシスを実施しようと思ったら、統計処理をする必要があることもまた事実です。Rと言う統計ソフトを使い、{meta}などのパッケージを使うことで、誰でも気軽に無料で統計処理をすることができます。しかし、無料とはいっても統計ソフトをインストールし、そのプログラミング言語をある程度マスターするのはハードルが高いです。実は私もRのインストールがうまくいかずに、はじめの数本の論文は全てクラウドのRStudioサービスを使いました。
そこで今回、データさえ揃えたら、インストールも登録も不要で誰でも簡単にペアワイズ・メタアナリシスを行うことができるウェブアプリを作成しました。このアプリだけで、ペアワイズ・メタアナリシスの論文に必要な解析が一通りできます。例えば、Journal of Affective Disordersに掲載されたうつ病に対する不眠の認知行動療法についてのメタアナリシスはこのアプリだけで必要な統計処理ができてしまいます。
データを準備する
系統的レビューで見つけてきた文献の中から、メタンリシスに必要なデータを抽出します。データはロング形式と言われる形式で整えるようにしてください。2値変数であればstudlab, treat, n, eventの4列が必須です。ロング形式では1つの行が1つの群に対応します。そのため、ペアワイズの研究では、各研究を2列で表現します。同じ研究名の列が2つ必要になります。それぞれ、treatの列に介入群 “intervention”、および、コントロール群”としてその群に割り付けられた人数nと、イベント数eventを入力してください。ここで、studlab列は文字列であれば何でも良いですが、treat列には”intervention”か”control”かを入力するようにしてください。どちらも小文字スタートです。連続変数の場合はstudlab, treat以外にn, mean, sdが必要になります。n, event, mean, sd列は半角数字をいれるようにしてください。サブグループ解析を行う予定であれば、subgroupという列も作って下さい。これは必須ではありません。
次の表に例を挙げます。
| studlab | treat | n | event | subgroup |
| Manber2008 | intervention | 15 | 5 | Active |
| Manber2008 | control | 15 | 1 | Active |
| Watanabe2011 | intervention | 20 | 8 | Active |
| Watanabe2011 | control | 17 | 1 | Active |
| Wagley2013 | intervention | 21 | 2 | Waitlist |
| Wagley2013 | control | 10 | 0 | Waitlist |
| NorellClarke2015 | intervention | 19 | NA | Active |
| NorellClarke2015 | control | 22 | NA | Active |
| Manber2016 | intervention | 75 | 31 | Active |
| Manber2016 | control | 75 | 15 | Active |
| studlab | treat | n | mean | sd | subgroup |
| Manber2008 | intervention | 13 | 9.5 | 6.3 | Active |
| Manber2008 | control | 15 | 14.3 | 5.1 | Active |
| Watanabe2011 | intervention | 20 | 10.6 | 4.91934955 | Active |
| Watanabe2011 | control | 17 | 15.9 | 4.94772675 | Active |
| Wagley2013 | intervention | 20 | 11.57 | 4.95 | Waitlist |
| Wagley2013 | control | 10 | 15 | 4.04 | Waitlist |
| NorellClarke2015 | intervention | NA | NA | NA | Active |
| NorellClarke2015 | control | NA | NA | NA | Active |
| Manber2016 | intervention | 56 | 8 | 6 | Active |
| Manber2016 | control | 48 | 11 | 8 | Active |
(前述の論文のデータの一部)
これができたら、自分のデータを解析する準備が完了です。
データをアプリに入力する
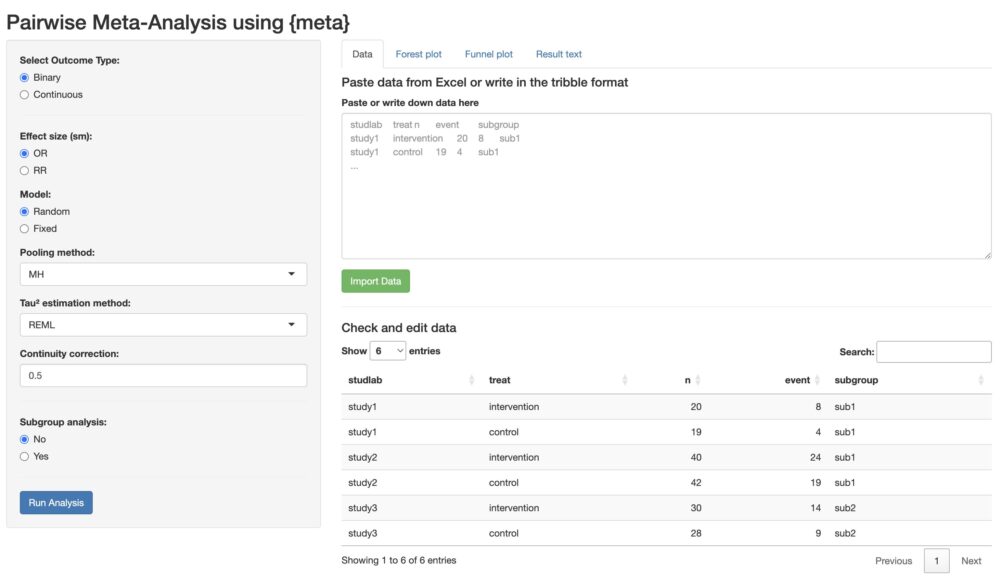
ウェブアプリを開いたら、左上のラジオボタン(①)で2値変数か連続変数かを選んでください。2値変数であればBinary、連続変数であればContinuousです。
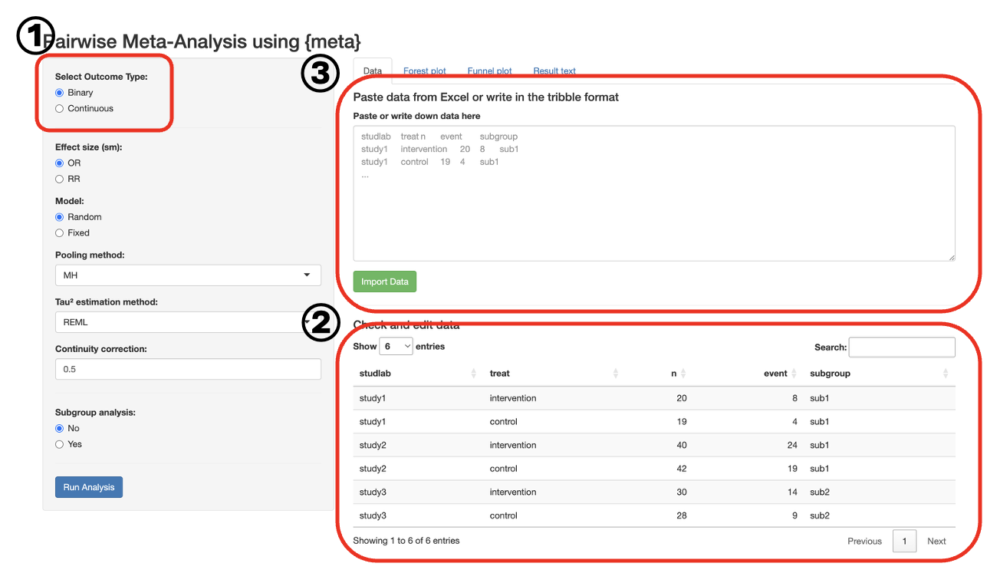
メインのパネルにプリセットされたデータ(②)が表示されます。アプリの機能を試すためにこのまま用いても良いですし、自分のデータを使いたい時は上の欄(③)にExcelからコピペをして、”Import Data”ボタンを押してデータをインポートしてください。
あまり使う事は無いかもしれませんが、エクセルからのコピペ以外にもtibble::tribble()形式で直接入力することでもデータをインポートできます。
パラメーターを設定する
2値変数を選択した場合、オッズ比(OR)、ランダム効果モデル、MHという統合方法、REMLという異質性の推定方法、0イベントの補正に0.5を用いる、という初期設定になっています(④)。
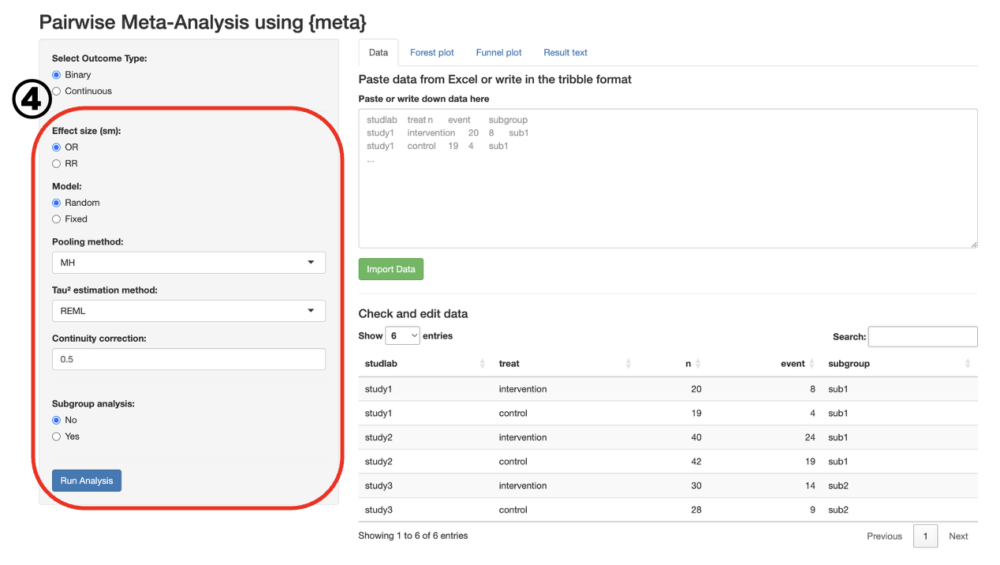
多くの場合このままの設定で解析をしてもらって大丈夫です。”Run Analysis”ボタンを教えて下さい。レアイベントの解析を行うときは、固定効果モデルを使うことがあります。その際、Pooling methodはPetoを用いるのがよいと言われています(ORのみ)。
連続変数を選択した場合も、初期設定(SMD, ランダム効果、REML)のまま解析をして、ほとんどの場合は問題ありません。何らかの仮定があって固定効果モデルがより適切ということがあれば、選択することもできます。また、すべての単位が同じで、かつその単位をそのまま使うほうが理解しやすい単位である場合(例えば、体重のkg、HbA1cの%など)は、SMDではなく、MDを用いても良いでしょう。
サブグループ解析は必須ではありません。デフォルトはNoになっています。サブグループ解析をYesにすると、下にサブグループを入力する欄が出現します。ここに順番にサブグループの名前をコンマ区切りで入力してください。入力された順に、forest plotの上からが表示されます。
Forest plotを微修正する
パラメーターを設定し、“Run Analysis“ボタンを押すと、自動でforest plotが表示されます。できるだけ見やすいように自動で調整を加えています。上記の表のデータをインポートしてデフォルトの設定で解析した結果が下記です。
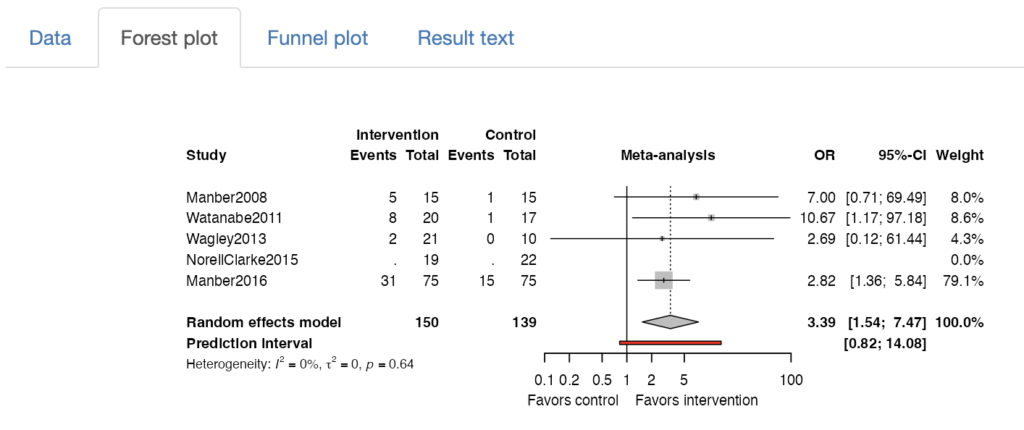
下の方にはパラメーターをさらに編集することができるようになっています。タイトルを編集することでforest plot内のタイトルが変わります。Label for intervention, Label for controlを上の方でIntervention, Controlと表示されているところを変更することができます。さらにLeft-side label, Right-side labelでX軸の下に表示される文言を調整できます。
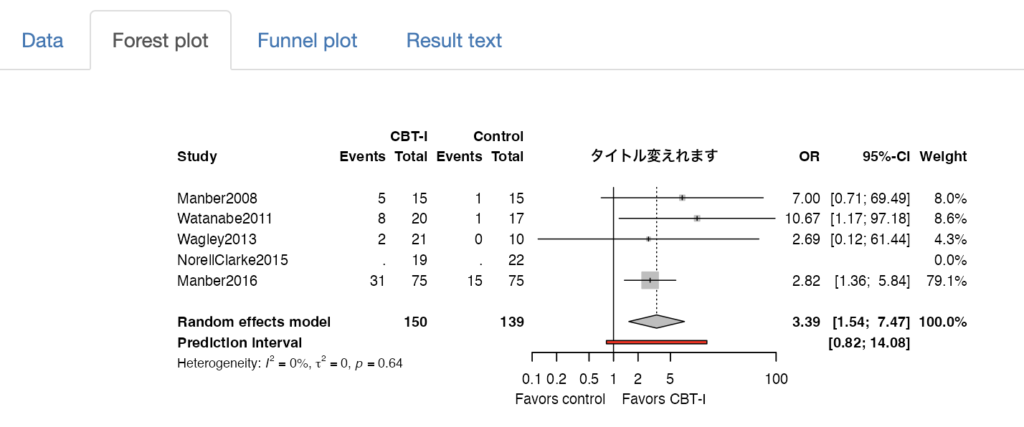
Forest plotの高さはデフォルトでは3-5研究程度を表示するときにちょうど良いように設定されています。もっと多くの研究を組み入れた場合はもっと縦長にする必要があるでしょう。Plot height (px)で調整してください。横幅はPlot width (px)で調整できます。
ちょうど良い図ができたら、スクリーンショットか右クリックで図を保存してください
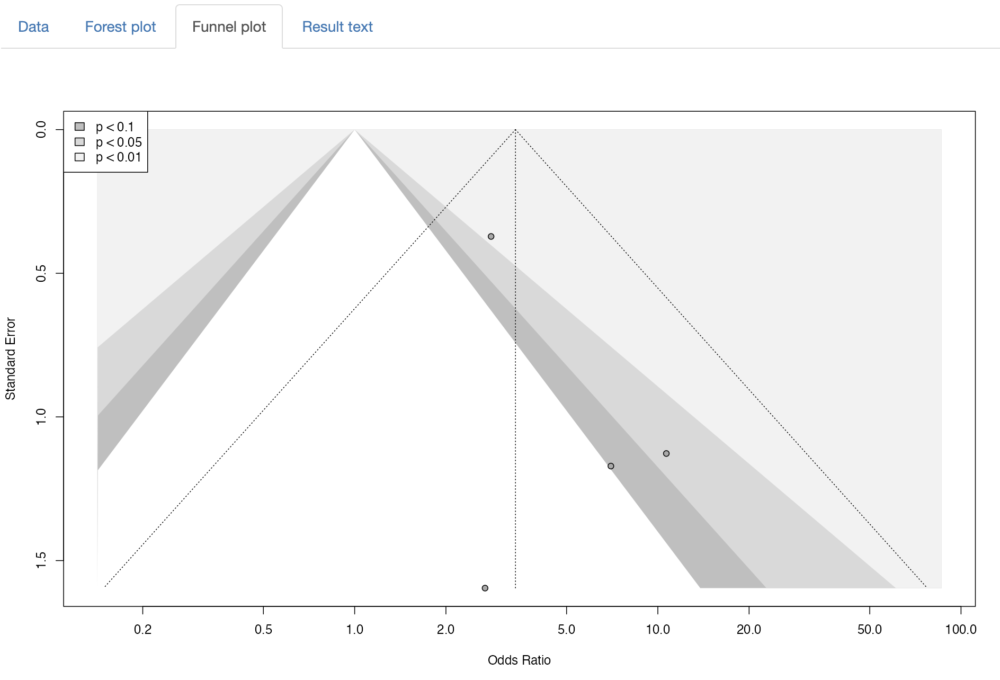
Funnel plot
Contour-enhanced funnel plotが自動で作成されます。スクリーンショットか右クリックで図を保存しておいてください。
Result text
メタアナリシスの結果をテキストでも表示できるようになっています。パラメーターの設定などもテキストの中に反映されるようになっていますので、このテキストもぜひ保存しておくようにしてください。
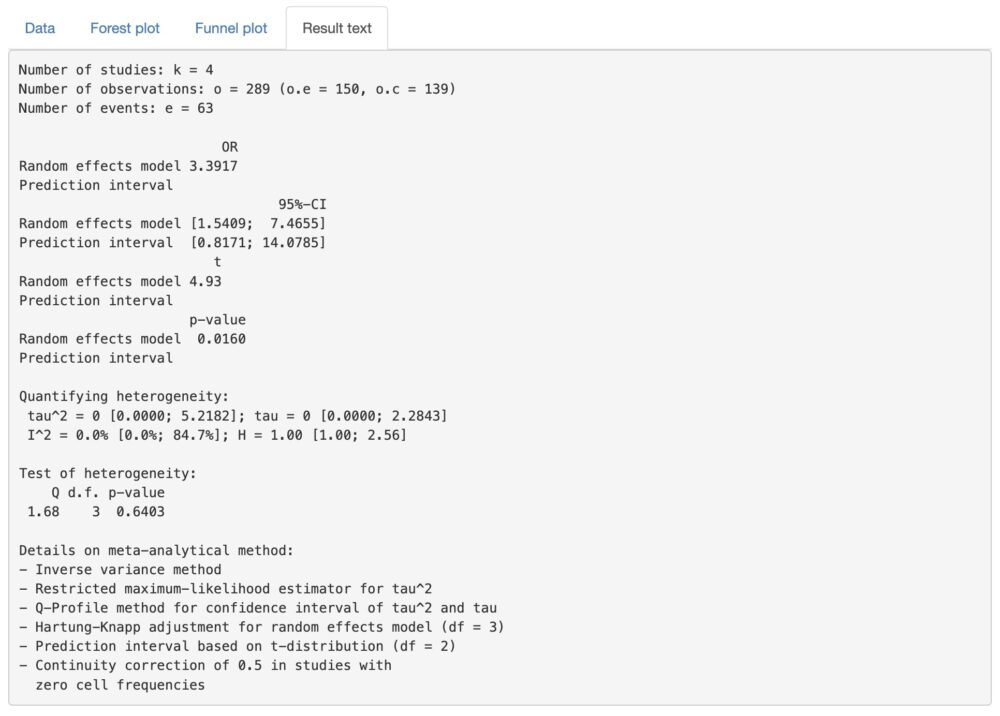
オープンサイエンスの潮流として、できるだけ研究で用いたデータセットや解析のスクリプトを公開することが推奨されるようになっています。このアプリを用いると、スクリプトを公開することはできませんが、データセットを公開することはできます。また、このテキストファイルを保存して公開することでどのような設定で行ったかということが他の人にもわかるようになります。

名古屋市立大学医学部卒業後、南生協病院での初期研修を経て、東京大学医学部附属病院精神神経科、東京武蔵野病院で専攻研修。日本専門医機構認定精神科専門医、精神保健指定医。臨床と並行してメタアナリシスを中心とした臨床研究を主導。筆頭著者として、JAMA Psychiatry, British Journal of Psychiatry, Schizophrenia Bulletin, Psychiatry and Clinical Neuroscienceなどのトップジャーナルに論文を発表。不眠の認知行動療法 (CBT-I) などの心理療法や、精神科疾患の薬物療法について、臨床で抱いた疑問に取り組んでいる。メディア報道・講演など。
免責事項:当ウェブサイトは所属団体の意見を代表するものではありません。管理人は、細心の注意を払って当ウェブサイトに情報を作成していますが、情報の正確性および完全性を保証するものではありません。当ウェブサイトの情報もしくはリンク先の情報を利用したことで直接・間接的に生じた損失に関し、管理人は一切責任を負いません。
